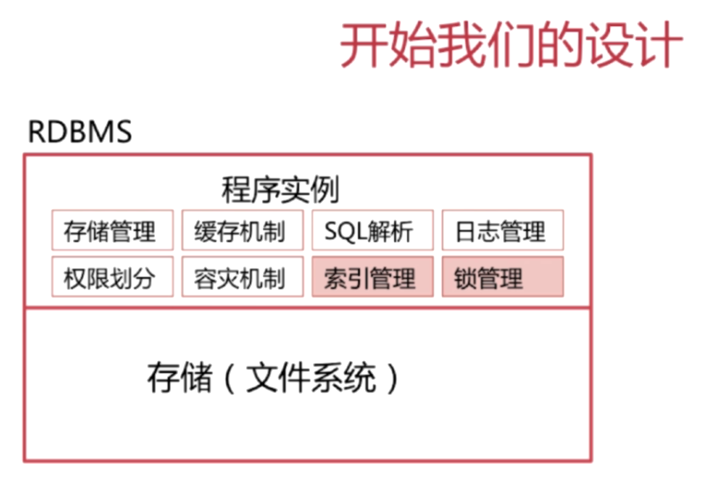
RDBMS数据库的设计
索引模块
为什么要使用索引
- 快速查询数据
索引的数据结构
- 生成索引,建立二叉查找树进行二分查找;
- 生成索引,建立B-树结构进行查找;
- 生成索引,建立B+树结构进行查找;
- 生成索引,建立Hash结构进行查找;
优化索引
树的高度决定了IO次数,所以为了降低IO次数,减少时间复杂度,我们要降低树的高度,使用B树;
B-Tree
定义 

合并打乱上借下移保持平衡
B+树
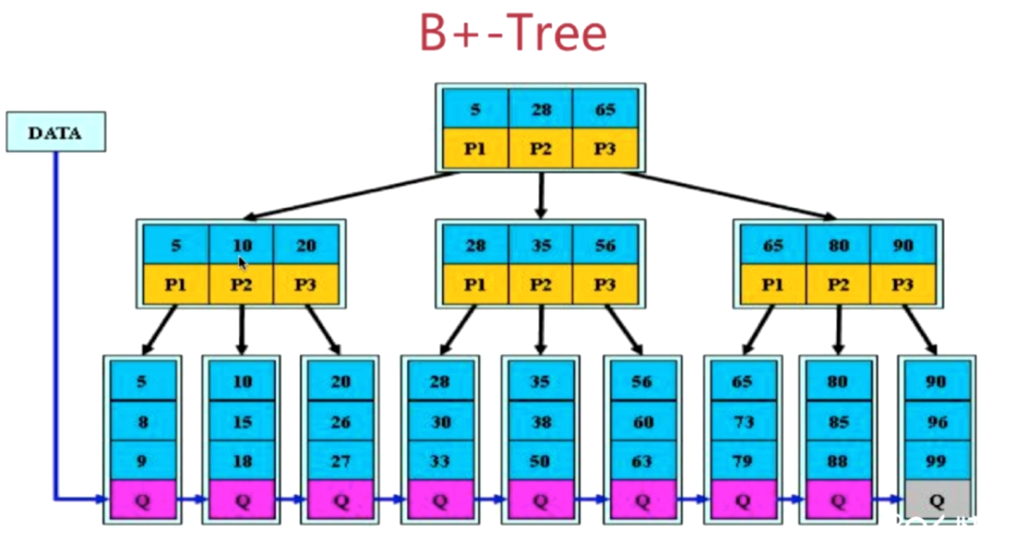
Q代表指针
B+树更适合用来做储存索引
- b+树的磁盘读写代价更低;
- B+树查询效率更加稳定
- b+树更有利于对数据库的扫描;
Hash索引
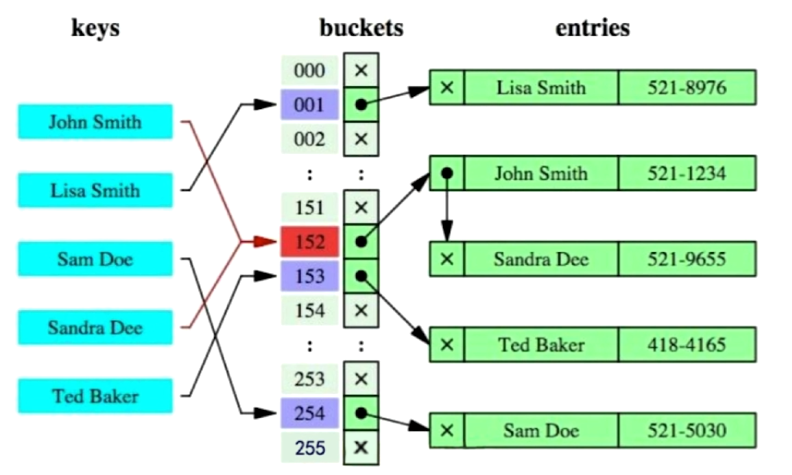
缺点:
- 仅仅能满足“=”,“in”,不能使用范围查询;
- 无法被用来避免数据的排序操作;
- 不能利用部分索引键查询;eg:组合索引;
- 不能避免表扫描;
- 遇到大量Hash值相等的情况后性能并不一定就会比B+效率高;
BitMap索引位图索引
orcle
优点:一个节点能储存大量数据,类似于叠加cpu;
缺点:锁特别多;不适合高并发;
密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码值都对应一个索引值;
- 稀疏索引文件只为索引码的某些值建立索引项;(叶子节点只保存了叶子节点的zhu键值和地址信息)
Mysql都是稀疏索引;
InnoDB都是密集索引

比较
相同点:都不支持hash索引
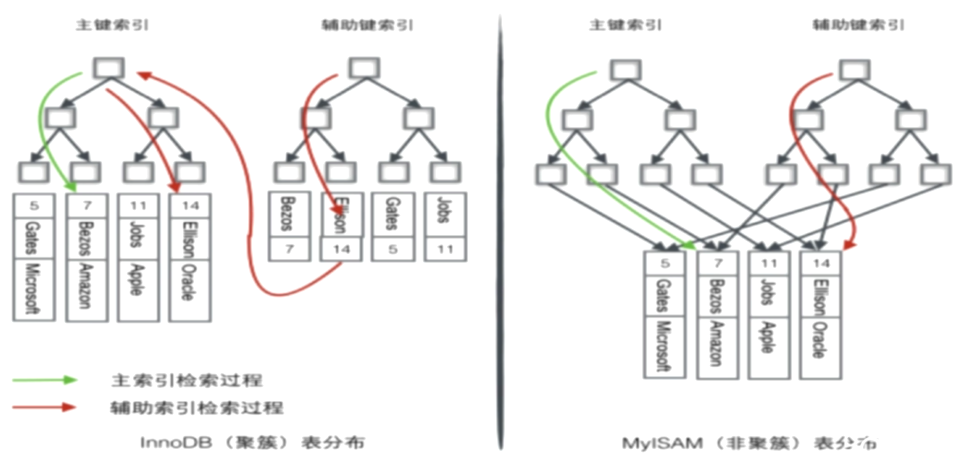
密集索引直接在节点存储行,通过主键可以直接查询,使用辅助查询的话运行两次B+树即可;
而稀疏索引,主树和辅助树储存的信息都一样,所以不用访问主树即可找到;索引和数据是分开的;
如何调优索引
定位并优化慢查询Sql;
思路
根据慢日志定位慢查询sql;
show variables like '%quer%' set global slow_query_log = on; set global slow_query_time = 1; show status like '%slow_queries%'改配置文件
使用explain等工具分析sql (在语句前加上explain)
Explain关键字段解释
type:

extra:
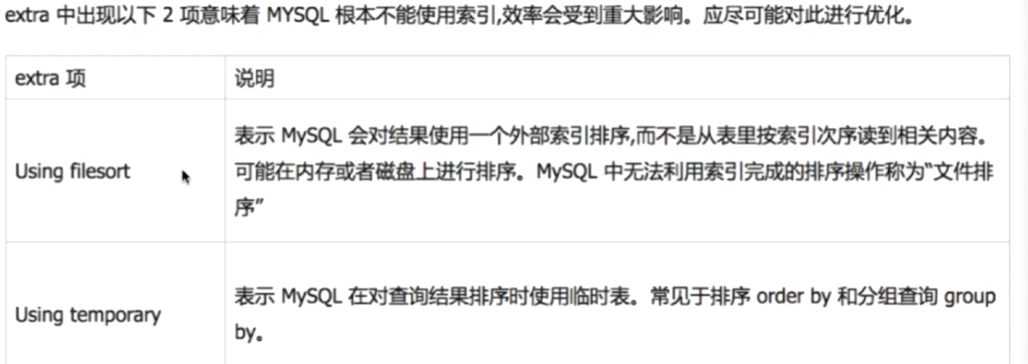
修改sql或者尽量让sql走索引
- 走index效率提高33%

- 走index效率提高33%
联合索引
最左匹配原则
成因
索引是建立得越多越好吗?
